
Hello TranscribeというMac/iPhone用の音声書き起こしユーティリティーがバージョンアップして、精度が高いWhisper Large-V3言語モデルが使えるようになったので、レポートします。先日のOpenAI DevDayで発表され、さらに精度が上がったモデルなので、とても高品質な結果が得られました。
[追記 2024/04/10] 最近、さらに制度が高いWhisperAXを使い始めました!これについてもまた近いうちにレポートします。ご期待ください ;)
Whisperはコマンドラインで使えるけれど…
Whisper自体は、必要な設定さえすればコマンドを入力することで使えます。ローカルに環境をセットアップして使うことも可能です。私もその環境は作っています。ただね、GUIで簡単に操作したいわけ。どっちが楽かは、人次第。
openai/whisper-large-v3 · Hugging Face

Whisper Large V3 – a Hugging Face Space by choimirai

Hello Transcribeって、どんなユーティリティー?
そこで、Hello Transcribe。これは、MacとiPhone、iPad用の音声文字起こしユーティリティーです。ChatGPTを開発しているOpenAI社のWhisperとWhisper.cppを使っていて、日本語の精度も非常に高いのが特長です。特長や制限の大半が、Hello TranscribeじゃなくWhisperのそれなんですが、一応紹介してみます。

- 音声メモやPodcast、あらゆる音声ファイル(多くのフォーマットに対応)から書き起こしが可能。
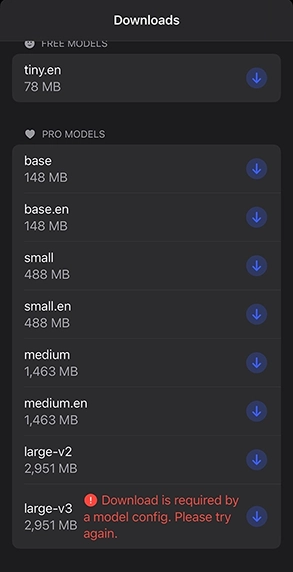
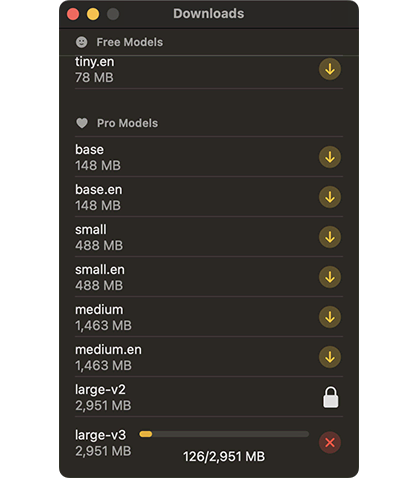
- 日本語も非常に高い精度。予めビルトインされている言語モデル以外に、プロにアップグレードしてbase/small/medium/largeなど、いろいろなモデルデータをダウンロードして使える。
- オーディオファイルだけでなく、ビデオファイルもサポートしていて、写真.appのライブラリーを直接指定できる。
- マイクからのライブ書き起こしにも対応しているので、口述筆記にも対応。
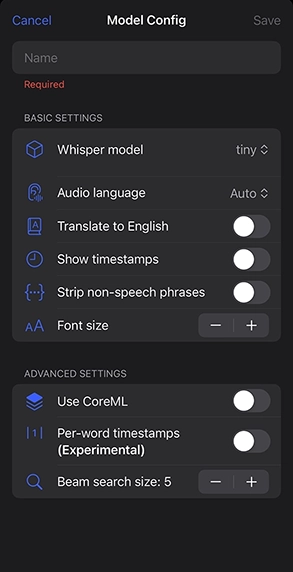
- タイムスタンプを入れるか、認識できなかった部分を「…」で埋めるかをオプションで選択可能。
- デバイス上で処理され、プライバシーが守られる。結果はiCloudに暗号化して保存される。
- 書き起こしたテキストは、VTT(WebVTT:Web Video Text Tracks)またはSRTファイル(Sub Rip Subtitle)を書き出せるので、ビデオに字幕を追加するのも楽。
- 多言語に対応。英語に翻訳も可能。
Hello Transcribeを使うと幸せになれる人
- Terminalでコマンドを叩くより、GUIで操作したい合理主義者
- 会議で議事録を取りたいビジネスユーザー
- 取材や打ち合わせ、イベントから文章を起こさなければならないライター
- 多言語の環境があるインターナショナリスト
- 授業やトレーニングで音声メモを取ってる学び人
- セキュリティーやデバイスの管理権限があるか、関係者と調整できる人たらし
Hello Transcribeのココがいい!
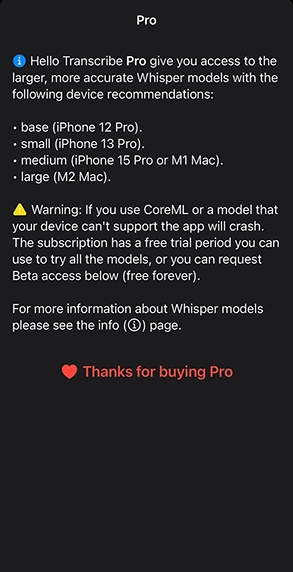
- 精度が高いWhisperのLarge言語モデルが使える(有料アップグレード推奨というより必須!)。一部の同音異義語や不明瞭な発音、言い淀み、言い間違いを拾ってしまったり、商品やサービス名を間違える以外は、ほぼ完璧に近い精度。
- Pro版はサブスクリプションじゃなく、1,000円という超リーズナブルな買い取り(別に、全モデルが使える300円/月のサブスクプランもあるものの、Largeだけ買えば十分)!Mac App Storeで買って、複数のデバイスで使え、iPhoneアプリもそのまま使える。
- スピードもそれなり。1時間ほどの音声で、約18分掛かった(詳細は後述)。別に速くはないが、待てないほどではない。
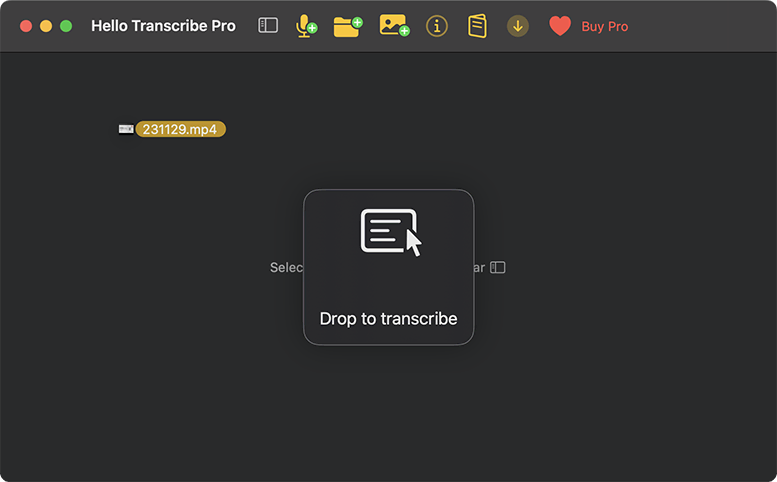
- 迷いようがない、シンプルなUIで使いやすい。書き起こしたいファイルをドラッグ&ドロップするだけ。
- オーディオのIN/OUTを接続したりしなくていいので、スピーカーがオフでも動作する。
Hello Transcribeのここは要注意
- 処理の負荷がかなり高いので、他のアプリケーションを使いながらは非推奨。MacならApple silicon前提で、Largeモデルを使うならM2以上(M1 MacはMediumモデルまで)。
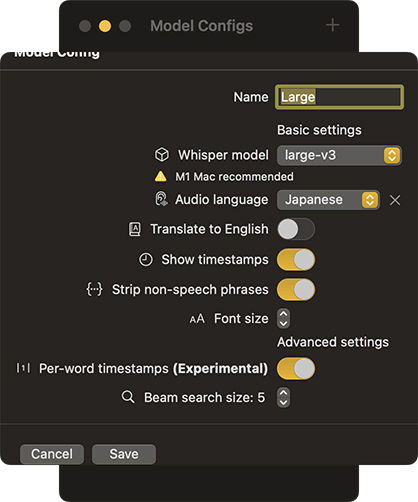
- 使うデフォルトのモデルを設定できない。Large-v3を使う場合は、いちいち選択・確認しなければならない。途中で設定を変えるたびに、最初から認識がリスタートされてしまう。
- 処理の進み具合が、プログレスバーやパーセンテージなどで表示されないのでわからない。終了しても、チャイムなどで知らせてくれない。
- ビデオファイルや、マイクからの直接認識は、使い勝手に難あり。音声ファイルを認識させるのがオススメ。
- テキストは書き出すか削除するかだけ。アプリケーションに保存しておくことはできない。アプリケーションが途中で終了した場合でも、そこまでのログは残らない。
- 方言や専門用語が多かったり、ノイズ混じりだと精度は落ちる。固有名詞などの辞書学習機能はない(これも恐らく「今はまだ」)。
- 複数話者の区別はできない。
- VTTファイルで書き出しても、標準ではQuick Lookできない。できても日本語は文字化けする。
iPhoneで使うのはあまりオススメできない
iPhoneで使うのは、あまりオススメではないかも。かなり警告されます。他のアプリを全部終了するように警告されますし、実際、処理中の本体もかなり熱くなります。Largeモデルを使うのは非推奨(iPhone 15 ProでもMediumモデルまで)。


Hello Transcribeの基本的な使い方
- Hello TranscribeをMac App Storeからインストールして、起動する。
- マイクへのアクセスなど、各種セキュリティーをmacOSで許可する。
- Hello Transcribe Pro版ライセンスを購入し、追加モデルをダウンロードする(有線またはWi-Fi推奨)。
- オーディオまたはビデオファイルをドラッグ&ドロップするか、マイクをアクティブにして、処理をスタート。
- 設定を開いて、使いたいモデルやオプションを設定する。
- 処理が終わったら、テキストを外部に書き出すかコピー&ペースト、共有して確認する。

Hello Transcribeを試してみた
Hello Transcribeのインストールとセットアップが終わった後、実際に使ってみた様子はこんな感じです。
デバイス:Apple Mac mini Apple silicon M2 Pro
メモリ:16 GB
OS;macOS Sonoma 14.1.2
- まず、メールやDropbox、Photoshopなど、メモリを消費しがちなアプリケーションやユーティリティーを終了させます。バックグラウンドで動作するユーティリティーも、終了または停止に。Webブラウザーは起動したままにしましたが、通知などはオフです(私が使っているChrome互換のWebブラウザーSidekickでは、複数開いたタブは、バックグラウンドでスリープ状態になるのが便利)。
- 今回は、1字間ほどのZoom会議のビデオから文章を書き起こしました(オーナーは他社)。共有されたビデオファイルをHello Transcribeのウインドウにドラッグ&ドロップすると、自動的に処理が始まります。
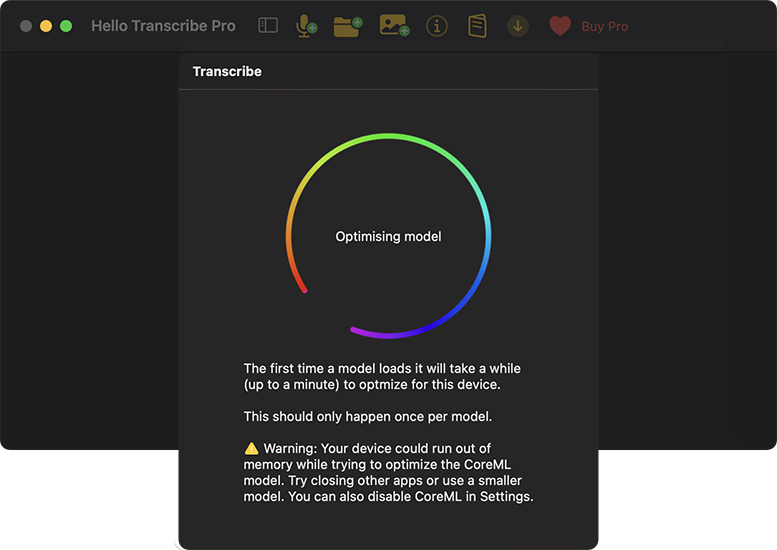
- 一旦、停止するか、そのまま「Model Config」を「Large」に切り替え、オプションも設定します。モデルの初回起動時には、初期化をしばらく待つ必要があります。変更を[Apply]すると、処理がリスタートします。
- 途中、他の作業をしない・スリープさせないことを推奨します。普段は意識しないMacのファンが、回転音を鳴らして回り出しました。アクティビティモニタで確認したところ、一時的にCPUの処理が100%を超えていました。
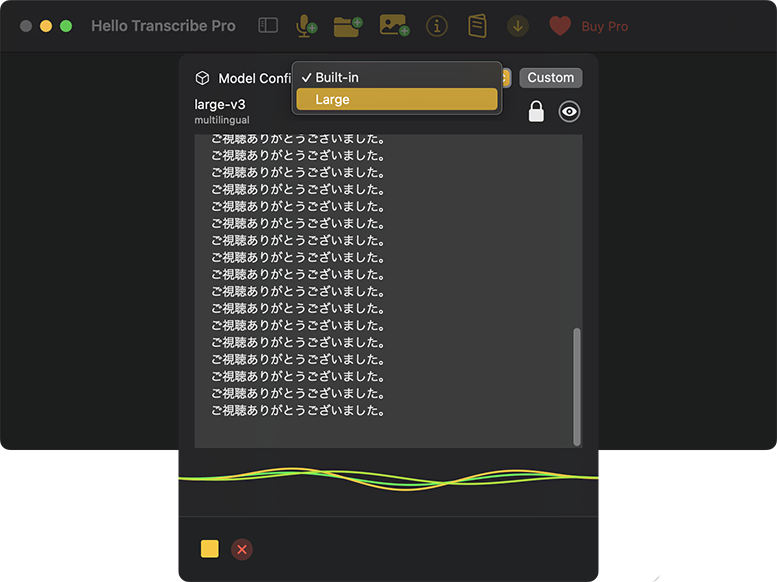
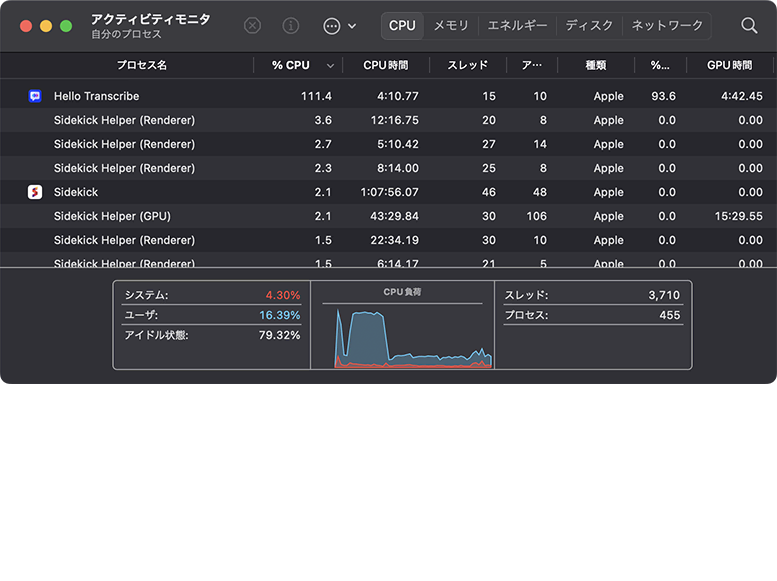
- 進捗がわからないので、時々チェックした方が良さそうです。音声のブランク部分(?)が、なぜか「ご静聴ありがとうございました。」の文字列で連続して埋められてしまいました(意味不明)!。結局、途中で処理が止まることが複数回あったので(再現性あり)、ビデオから必要な部分のオーディオトラックだけを抜き出して保存し、再挑戦!
- 今度は、それなりに進みました。1時間ほどの音声で、約18分掛かって終了です。処理ウインドウ左下のボタンが、■の[停止]から[↑]の書き出しに変わったり、波形が止まることぐらいでしか、終了したことが分かりません。今回は、vttファイルに書き出しました。
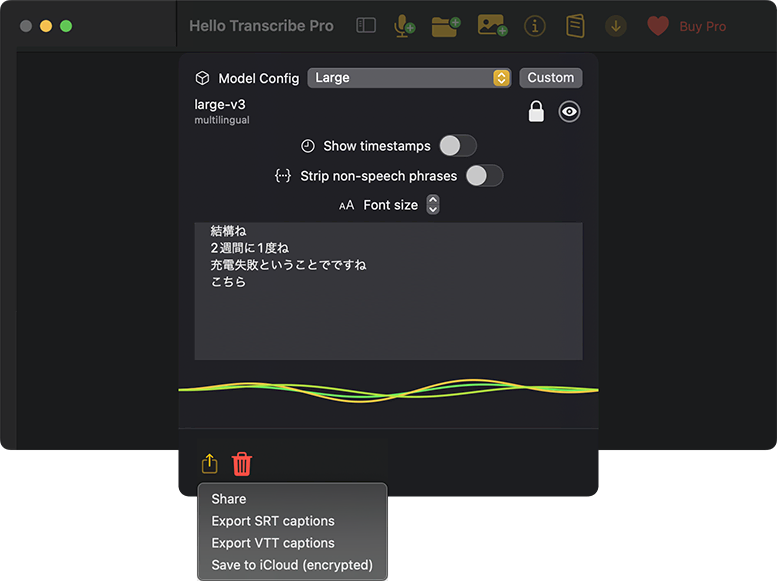
- vttファイルをエディタで開いて編集します。オプションで付けたタイムスタンプを、やっぱり消したくなったので、正規表現で以下を削除(置換)しました。
[0-9]{2}:[0-9]{2}:[0-9]{2}.[0-9]{3} –> [0-9]{2}:[0-9]{2}:[0-9]{2}.[0-9]{3} - ほぼ、そのまま議事録や原稿として使えるレベルです。Microsoft Teamsで自動認識されたテキストと比較するまでもありません。ただ、コーパス単位で改行が入ってしまっているところもあるので、見やすく整形する必要はあります。後は、製品名や固有名詞を中心に編集します。「させていただく」「という」「おります」といった、話者ごとの癖を処理したり、ここから先は人間のエディターの仕事です。
YouTubeビデオとマイク入力でもテストしてみた
まず、25秒ほどのショートビデオで試した例はこんな感じです。ソースはこちら。
成田修造「AIに恋する時代が来る」 #chatgpt #AI #恋 #pivot – YouTube
- 書き起こしそのまま
バーチャルな物体に恋をする時代
多分今来てますよ
アメリカではそういうものがバカ売れしてるわけですよ
アイドルみたいな
ゾーンに恋をしてそこと生活している生徒活動までするんだよそういう時代になって くるわけですよ
人は自然と順応しているつからかみんな生活の中でやや浸透させていて自分の生活を 改善しているなり
あさせているのかっていうことをみんな繰り返しながらやっていく - 編集後(太字部分が修正)
バーチャルな物体に恋をする時代
多分今来てますよ
アメリカではそういうものがバカ売れしてるわけですよ
アイドルみたいな
像に恋をしてそこと生活している生殖活動までする みんなそういう時代になってくるわけですよ
人は自然と順応しているつからかみんな生活の中でAIを浸透させていて自分の生活を 改善しているなり
悪化させているのかっていうことをみんな繰り返しながらやっていく
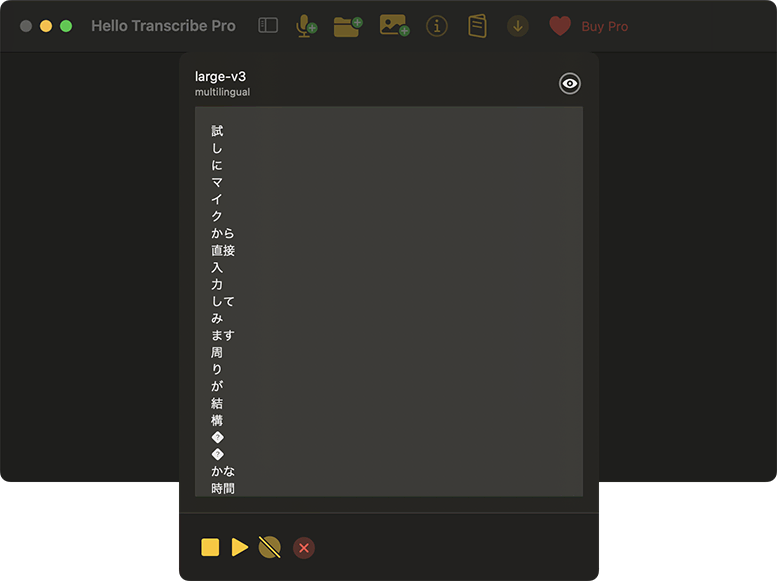
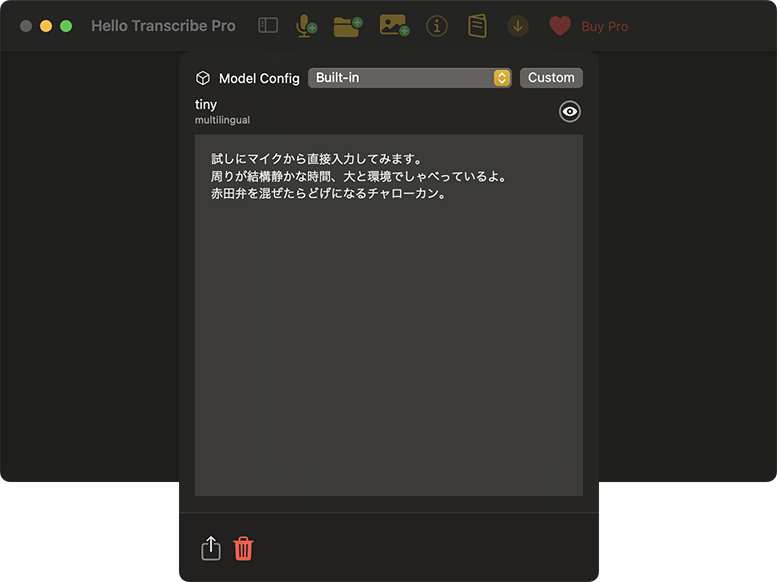
また、マイクから直接入力した結果は、これ。なぜか改行だらけで使い勝手が悪いようです。
- マイクではなく、ファイルからの書き起こしそのまま
試しにマイクから直接入力してみます。
周りが結構静かな時間、大と環境でしゃべっているよ。
赤田弁を混ぜたらどげになるチャローカン。 - 編集後(太字部分が修正)
試しにマイクから直接入力してみます。
周りが結構静かな時間帯と環境でしゃべっているよ。
博多弁を混ぜたらどげんなるっちゃろーか。
こうして見ると、結構な割合でミスしてるようにも思えますが、これが1時間程度の長さだったり、喋り手の癖や録音状況でも変わることを考えると、前述の通り制度は高いと思います。
内容や条件次第ですが、書き起こしたテキストはそのまま使うよりも、ChatGPTでぎゅっと要約して使うのがさらに楽かも。その方が、細かいてにをはを気にしなくて済むメリットもありそうです。ただ、そう遠くない将来、ビデオ会議終了と同時に、それなりの議事録ができるはずなので、それ以外の用途にも期待したいですね。
そういえば、Google Pixelでは、本体だけで精度が高い書き起こしが可能だとも聞きます。機会があったら比較もしてみたいと思います。